 Code
Code Dataset
DatasetBuild a Taxonomy
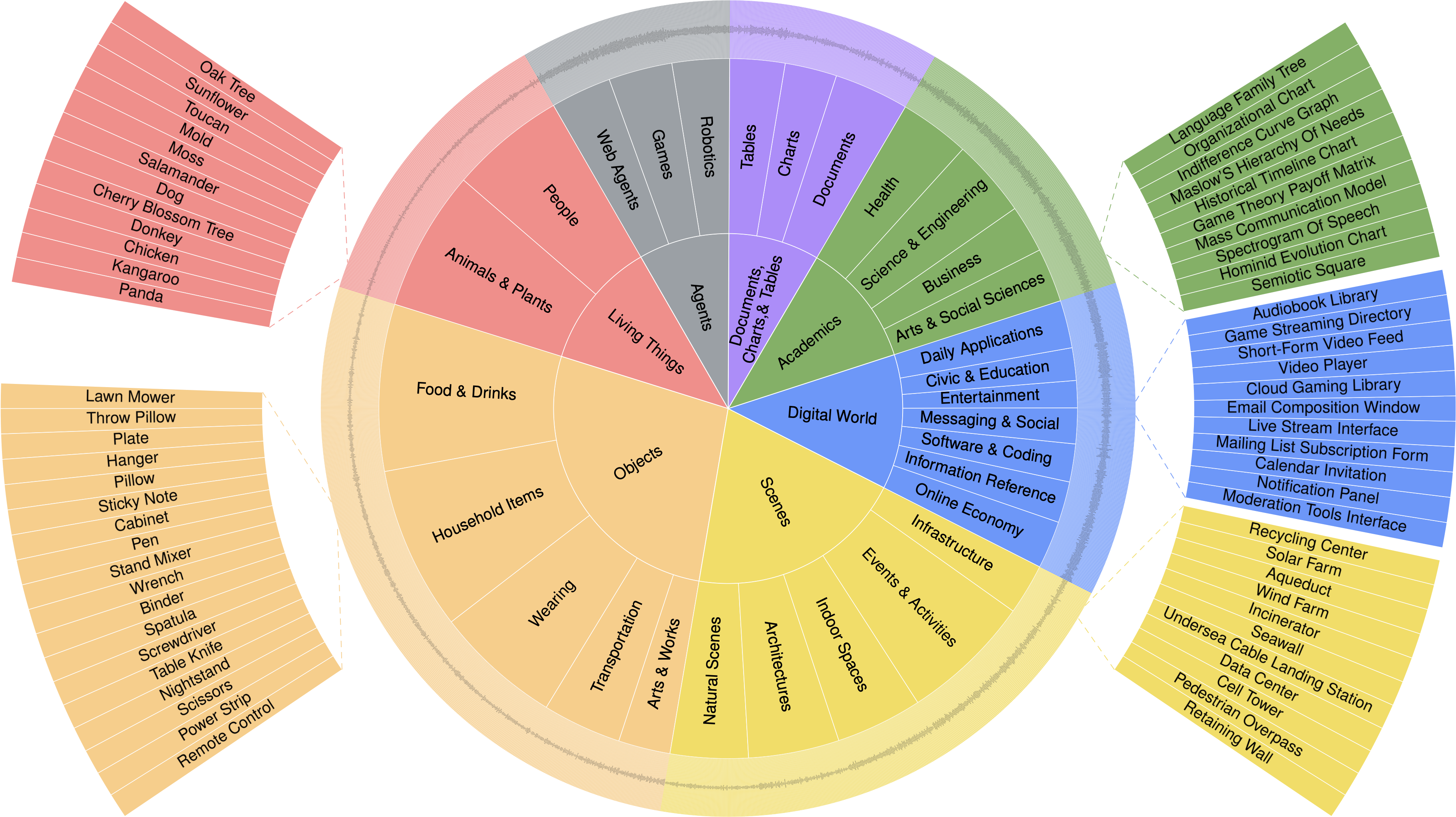
Start from seven high-level visual domains, expand into subdomains, then fine-grained concepts.
A Challenging and Visually Diverse Multimodal Reasoning Benchmark
Real-world multimodal systems must reason reliably across diverse visual settings. Yet many benchmarks expand task types without capturing the breadth of open-ended visual inputs models encounter in practice.
WorldBench addresses this gap with 2,000 human-curated questions drawn from a broad taxonomy of visual concepts. Both embedding-based measurements and human pairwise evaluations show that WorldBench is more visually diverse than existing diverse benchmarks, and it is difficult for frontier models: the strongest evaluated model reaches only 64.0% average accuracy.
Princeton University · NYU · University of Waterloo · Meta FAIR
To evaluate visual reasoning, the images must vary as much as the tasks. WorldBench starts from a taxonomy of 2,000 visual concepts across seven domains, then samples broadly from real-world, digital, document, academic, and agentic visual content.
The benchmark construction follows outward from the taxonomy: define coverage, curate representative images, then write questions that expose model failures.
Start from seven high-level visual domains, expand into subdomains, then fine-grained concepts.
Select high-quality, non-iconic images that represent each concept without collapsing into object-centric views.
Manually refine natural questions until frontier models fail, then review for single-answer validity.
The top proprietary model, Gemini-3.1-Pro, reaches 64.0% average accuracy. The best open-source model, Qwen3.5-VL-27B, reaches 56.6%. No model gets above 75% accuracy in any domain.
| Model | Living | Objects | Scenes | Digital | Acad. | DCT | Agents | Avg |
|---|---|---|---|---|---|---|---|---|
| Gemini-3.1-Pro* | 62.0 | 60.7 | 61.4 | 71.4 | 64.0 | 73.8 | 62.0 | 64.0 |
| Gemini-3-Flash | 56.7 | 60.7 | 57.5 | 66.9 | 63.2 | 72.7 | 63.3 | 61.8 |
| Qwen3.5-VL-Plus-Thinking | 56.3 | 62.8 | 55.0 | 58.9 | 60.1 | 60.2 | 63.3 | 59.3 |
| GPT-5.4-Thinking (high) | 55.5 | 53.8 | 54.3 | 67.3 | 60.1 | 64.5 | 63.9 | 58.2 |
| Qwen3.5-VL-27B | 50.6 | 57.5 | 53.3 | 58.5 | 61.8 | 57.6 | 60.2 | 56.6 |
| Claude-Opus-4.7 | 46.1 | 52.8 | 51.3 | 59.3 | 57.0 | 58.7 | 56.0 | 53.7 |
| Grok-4.2 | 49.8 | 53.6 | 49.2 | 59.7 | 53.9 | 57.0 | 54.2 | 53.3 |
| GPT-5.4-Thinking (low)* | 51.8 | 48.4 | 50.3 | 58.1 | 53.9 | 61.6 | 58.4 | 53.0 |
| Qwen3.5-VL-35B-A3B | 48.6 | 52.6 | 52.2 | 50.4 | 57.0 | 59.3 | 54.2 | 52.9 |
| Kimi-K2.5* | 49.0 | 52.0 | 49.7 | 56.9 | 51.3 | 59.3 | 54.8 | 52.5 |
| Gemma-4-31B | 49.4 | 47.4 | 46.0 | 51.2 | 54.4 | 52.9 | 54.8 | 49.7 |
| Qwen3.5-VL-Plus-Instruct* | 45.7 | 49.4 | 45.1 | 55.2 | 47.8 | 49.1 | 51.2 | 48.7 |
| GLM-4.6V | 47.8 | 41.1 | 43.4 | 38.7 | 40.4 | 42.4 | 44.6 | 42.5 |
| InternVL-3.5 | 38.4 | 42.5 | 44.6 | 39.1 | 38.6 | 42.4 | 38.6 | 41.2 |
| Gemma-4-E4B | 34.3 | 33.6 | 29.7 | 38.7 | 36.8 | 39.0 | 37.3 | 34.6 |
Peach cells mark the best score in each domain or average. * Models used during question proposal.
Visual diversity is measured two ways: embedding metrics across three vision encoders and Bradley-Terry rankings from responses from 12 people. WorldBench is at or near the top under both measures among diverse multimodal benchmarks.
Effective rank and participation ratio are higher when images spread across more independent visual directions.
Bradley-Terry scores estimated from responses from 12 people.
The examples shown span the benchmark's visual domains, from natural scenes to documents, charts, interfaces, and agent environments. Option badges mark responses from GPT-5.4-Thinking (low), Gemini-3.1-Pro, Qwen3.5-VL-Plus-Instruct, and Kimi-K2.5; a reasoning trace from Qwen3.5-VL-35B is included alongside each example.

@article{yin2026worldbench,
title = {WorldBench: A Challenging and Visually Diverse Multimodal Reasoning Benchmark},
author = {Yin, Yida and Krishnakumar, Harish and Lee, Chung Peng and Zeng, Boya and Chai, Wenhao and Tong, Shengbang and Chen, Wenhu and Xu, Hu and Fu, Xingyu and Sarch, Gabriel and Korolova, Aleksandra and Liu, Zhuang},
year = {2026},
journal = {arXiv preprint arXiv:2606.06538},
}